A multi-lab effort to establish new standards for the collection and preprocessing of multilingual eye-tracking-while-reading data
MultiplEYE’s objective is to enable multilingual eye-tracking while reading data collection that can be used as a basis to study human language processing within psycholinguistic research or the evaluation and improvement of machine language processing within machine learning research. One of the biggest challenges of this project is the coordination between labs and languages mostly across Europe but also internationally.
The network of researchers covers almost all Europe and several International Countries. During its first year of implementation, MultiplEYE has made significant advancements in the ‘Data Collection’ process covering more than 20 languages (with already available texts for data collection in Albanian, Croatian, Chinese, Danish, German, English, Estonian, Lithuanian, Polish and work in progress for Arabic, Basque, Catalan, Czech, Dutch, Greek, French, Hebrew, Italian, Latvian, Portuguese, Romanian, Russian, Spanish, Turkish and Ukrainian). Still, MultiplEYE network is open for contributions in other languages.
The four core principles of MultiplEYE are consistency, quality, open access and diversity supported by three crucial documents delivered by MultiplEYE team: Data Management Plan, Data Sharing Policy and Data Collection Guidelines. These documents offer guidance for anyone going through the data collection process, covering everything from lab protocols to experimental setup, stimuli presentation, comprehension questions, data pre-processing and data quality review.
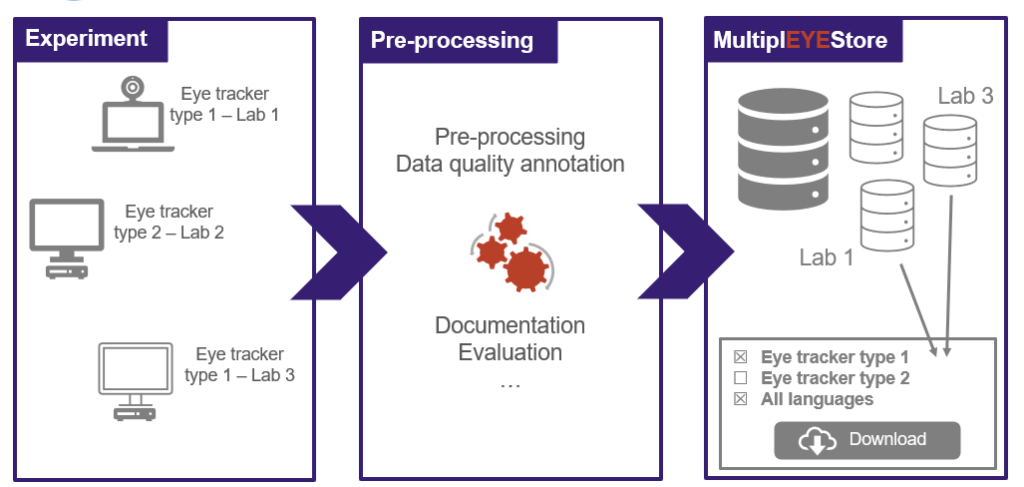
The experimental flowchart aims to help each participant taking part in the action, but not only. Everyone who is wishing to contribute, can easily follow the flow of the work and see where they can contribute. It also establishes a standardised framework for future experiment implementations across different laboratories.
After finalising the collection of the main stimuli text in the major part of the 21 languages involved, the focus is on finalising and translating the comprehension questions for each text. Regarding the comprehension questions, a specific guideline has been created, determining how the questions need to be designed to analyse eye movements compared to the received responses. Additionally, the MultiplEYE team has decided to include an extra session for psychometric tests, in order to collect more information from experiment participants.
All the data gathered from the eye-tracking experiments and the additional tests will be stored in the MultiplEYEStore, easily accessible and downloadable from anyone interested. To ensure consistency across different labs, an experimental setup in Python is under development, offering a standardised software environment. The experiment is designed to accommodate various eye-tracking devices, promoting diversity in equipment usage and facilitating the work of different labs.
MultiplEYE team introduced its intermediate results in the Crosslinguistic Perspective on Processing and Learning (X-PPL) Workshop held in Zurich from November 6th to 8th, 2023, and exchanged ideas and insights with the growing community of researchers working to expand the diversity of languages in the scope of experimental or corpus research on adults or language acquisition.

Deborah Jakobi, an active member of MultiplEYE, representing poster’s authors Deborah N. Jakobi, Maroš Filip, Ramunė Kasperė, Nora Hollenstein, Lena A. Jäger and The MultiplEYE Team presented the work-in-progress poster entitled “MultiplEYE: A multi-lab effort to establish new standards for the collection and pre-processing of multi-lingual eye tracking-while-reading data”. She showcased the objectives of MultiplEYE and the main achievements so far, attracting new potential collaborators in this ambitious initiative.