MultiplEYE is a COST Action funded by the European Union. COST Actions are research networks supported by the European Cooperation in Science and Technology, or COST for short. As a funding organisation, COST supports our continuously growing network of researchers across Europe and beyond by providing financial means for conducting several types of networking activities. These activities include working group meetings, training schools to share skills with younger researchers and scientific research visits, among others.
The name “MultiplEYE” is a word play combining “multilinguality” or “multiple languages” with “eye” from “eye-tracking”. The project title of the MultiplEYE COST Action is: Enabling multilingual eye-tracking data collection for human and machine language processing research. This means that the MultiplEYE COST Action aims to foster an interdisciplinary network of research groups working on collecting eye tracking data from reading in many languages. The goal is to support the development of a large multilingual eye tracking corpus and enable researchers to collect data by sharing infrastructure and their knowledge between various fields, including linguistics, psychology, and computer science. This data collection can then be used to study human language processing from a psycholinguistic perspective as well as to improve and evaluate computational language processing from a machine learning perspective.
Eye tracking is the process of measuring either the point of gaze — where you are looking at — and the movements of the eyes between fixed points of gaze. The device used to measure the eye positions and eye movements is called an eye tracker. It consists of an infrared camera, using a light frequency that does not bother or hurt the human eye. With the help of image recognition algorithms the eye tracker is able to estimate gaze points very accurately from knowing the position of the head and eyes, the distance to the screen a participant is looking at and the position of the eye tracker.
Eye-tracking is a useful technology for a multitude of applications. For example, it can help to detect tiredness while driving or it can support the diagnosis of attention and language disorders. In addition to other applications in the medical domain, eye-tracking is also used in gaming, marketing and human-computer interaction.
Why is eye-tracking while reading especially interesting for our project?
As you read these words, an eye tracker can follow your eye’s movements over the text. This provides information about how long you spend looking at a text, or more specifically, how long you spend on each word, which words you skip, and which words you dwell on.
As your brain is simultaneously processing the content of the text, your eye movements reflect a lot of the linguistic and cognitive processing going on almost in real time. Thus, the recorded data is a gold mine of information about how we put together the meaning and grammatical structures of a text. It shows quite precisely which parts of the text we struggle with and which parts are easily readable.
The motivation behind MultiplEYE is that eye-tracking data is still sparse, especially for smaller languages. Such a large data collection is a challenge in terms of developing and agreeing on the experimental design, the complexity and types of the texts to be read by the participants. Other decisions that seem less relevant but are in fact very important, include the font type and size the text is presented in, the order of the texts, the experiment procedure and how the data will be processed.
But once completed, this dataset will allow us to investigate many topics related to psycholinguistics and computational linguistics. For example, we will be able to compare the reading behavior across different languages. Does the script, the Latin alphabet versus Cyrillic or Arabic scripts, have an impact on reading times? An example concerning the computational processing of text could involve using eye tracking data to advance artificial intelligence applications that imitate the human reading process. This could be used to build better machine translation systems or to improve the automatic extraction of keywords from text.
Receiving eye-tracking data from many different participants, reading texts in many different languages, will be a great foundation for our research. It will be the main factor to turn our research network into a successful endeavor.
It is our hope that we can clear the way for advancing research in various subfields of linguistics by supporting and connecting a large group of researchers. The main outcomes of the MultiplEYE Action will be a large dataset containing eye-tracking data in many languages and a platform for new collaborations leveraging this type of data.
Supported Languages
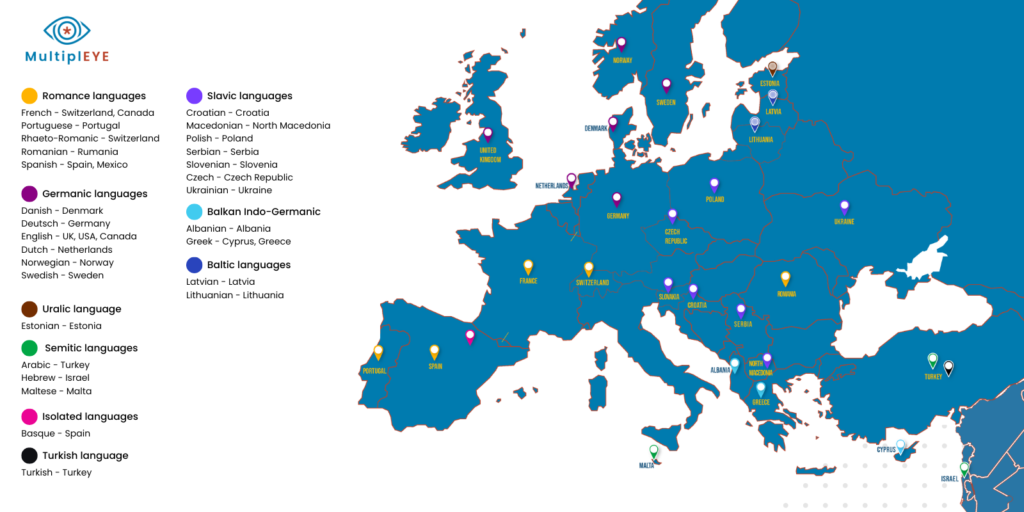
Note: MultiplEYE also supports languages beyond Europe (US, Canada, Mexico, Pakistan) and aims to broaden language coverage in the future.
Areas of Expertise Relevant for the Action
● Linguistics: Corpus Creation and Annotation, Databases, data mining, data curation, computational modelling.
● Psychology: Psycholinguistics: human language comprehension, language pathologies, L1 and L2 language processing, language acquisition, reading.
● Computer and Information Sciences: Natural Language Processing, Machine learning algorithms.
Action Details
Grant Holder: University of Zurich, Switzerland
Start of Action: 28 September, 2022
End of Action: 27 September, 2026
CSO approval date: 27 May, 2022